![[BANNER]](/templates/iceage/images/banniere.jpg)
Envoyé par unreal
Optimiser un disque ? Pour quoi faire ?
Les disques de la série Advanced Format WD ont une particularité intéressante : ils utilisent des secteurs physiques de 4ko au lieu des 512 octets habituels, taille utilisée depuis maintenant 30 ans. Pour assurer la compatibilité avec les systèmes existants (utilisant toujours 512 octets comme taille de secteur logique), le micro logiciel embarqué dans le disque réalise une opération de mapping. Ainsi, il fait rentrer 8 secteurs logiques dans un seul secteur physique.
Cela fonctionne parce qu'un système d'exploitation n'écrit jamais des blocs aussi petits. En effet, l'OS va poser son système de fichiers sur le disque et ainsi définir une taille minimale de bloc, 16ko par défaut sur UFS, par exemple.
C'est alors qu'on constate un problème potentiel. D'un côté nous avons le système d'exploitation qui veut écrire des blocs de 16ko, de l'autre nous avons un disque qui dispose de secteurs de 4ko, le tout communiquant sur un bus de 512 octets. Dans ce cas, il peut avoir un décalage faisant en sorte qu'un bloc du système de fichier soit écrit physiquement sur 5 secteurs au lieu de 4 :
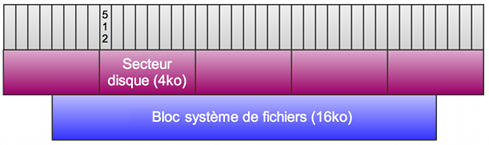
Il se produit alors une dégradation des performances à deux niveaux :
Test de débit avec formatage par défaut
Commençons par créer une nouvelle partition en suivant le Handbook FreeBSD, à savoir :
Une fois la partition créée et montée, il suffit de lancer Bonnie++ dans un dossier quelconque et d'analyser les résultats.
On constate que les performances sont inférieures aux attentes, indiquant potentiellement un mauvais alignement par rapport aux secteurs physiques.
Recherche du meilleur offset
Pour trouver l'alignement optimal, on recommence l'expérience précédente plusieurs fois en changeant l'offset. Il est également intéressant de faire un test d'écriture avec dd avant le test Bonnie, puis un test de lecture après pour comparer.
Pour réaliser ces mesures je me suis basé sur la configuration suivante :
Le graphe suivant résume les résultats :
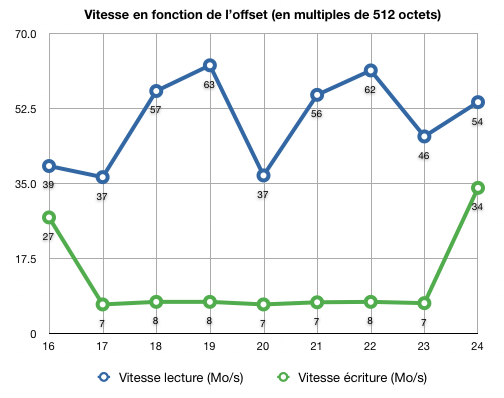
Le graphe montre clairement que l'alignement est assuré par défaut, contrairement à ce qu'on pouvait soupçonner. En effet, les meilleures vitesses en écriture sont obtenues avec un offset de 16 (défaut), puis avec un offset de 24, c'est-à-dire avec un offset supplémentaire de 4ko. Il est intéressant de noter que les performances en lecture séquentielle sont assez peu impactées par un mauvais alignement et on peut penser que c'est grâce au cache du disque qui contient forcément les secteurs lus récents, évitant ainsi une 2ième lecture.
Du coup, nous voilà pas spécialement plus avancés pour trouver l'origine des performances décevantes.
Une autre piste : la taille des blocs
Par défaut UFS utilise une taille de bloc de 16ko, ce qui semble en première approche convenable. Hélas ce n'est pas aussi simple : utiliser des blocs de 16ko implique une taille de fragments de 2ko parce qu'il est conseillé de préserver un rapport de 1/8. Selon le site de Sun, les fragments sont utilisés pour minimiser la fragmentation du système de fichiers en allouant des fragments de blocs plutôt que des blocs complets quand il n'en y a pas besoin.
Le problème est que ce disque WD ne sait pas écriture directement des blocs de 2ko, ayant lui-même des blocs de 4ko.
Pour étudier l'influence de la taille de bloc sur les performances, j'ai réalisé des benchmarks avec différentes tailles de blocs :
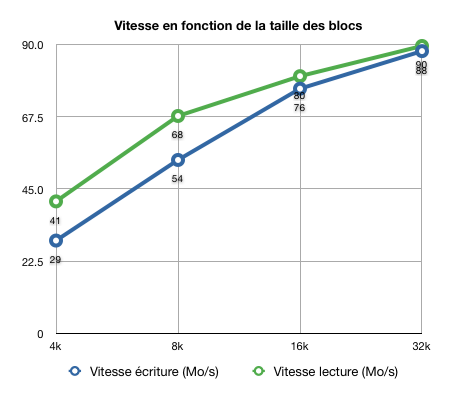
Il en ressort, sans surprise, qu'une taille de bloc de 32ko est bénéfique sur les performances, surtout que cela permettra au système de fichiers d'écrire systématiquement des blocs >= 4ko.
Conclusion
Contrairement à mes craintes initiales, l'alignement des secteurs est bien assuré si on opte pour un formatage natif. Par contre, il est intéressant d'augmenter la taille de blocs à 32ko en UFS parce que :
Historique
08/03/2010 - Version initiale
Les disques de la série Advanced Format WD ont une particularité intéressante : ils utilisent des secteurs physiques de 4ko au lieu des 512 octets habituels, taille utilisée depuis maintenant 30 ans. Pour assurer la compatibilité avec les systèmes existants (utilisant toujours 512 octets comme taille de secteur logique), le micro logiciel embarqué dans le disque réalise une opération de mapping. Ainsi, il fait rentrer 8 secteurs logiques dans un seul secteur physique.
Cela fonctionne parce qu'un système d'exploitation n'écrit jamais des blocs aussi petits. En effet, l'OS va poser son système de fichiers sur le disque et ainsi définir une taille minimale de bloc, 16ko par défaut sur UFS, par exemple.
C'est alors qu'on constate un problème potentiel. D'un côté nous avons le système d'exploitation qui veut écrire des blocs de 16ko, de l'autre nous avons un disque qui dispose de secteurs de 4ko, le tout communiquant sur un bus de 512 octets. Dans ce cas, il peut avoir un décalage faisant en sorte qu'un bloc du système de fichier soit écrit physiquement sur 5 secteurs au lieu de 4 :
Il se produit alors une dégradation des performances à deux niveaux :
- Lors des lectures, le disque doit lire 5 secteurs au lieu de 4
- Lors des écritures, le disque doit d'abord lire les deux secteurs incomplets, calculer l'intersection avec les nouvelles données, puis ré-écrire les 5 secteurs
Test de débit avec formatage par défaut
Commençons par créer une nouvelle partition en suivant le Handbook FreeBSD, à savoir :
# dd if=/dev/zero of=/dev/ad10 bs=1k count=1
# bsdlabel -Bw ad10 auto
# bsdlabel -e ad10
# newfs /dev/ad10
# mount /dev/ad10a /mnt/temp
# bsdlabel -Bw ad10 auto
# bsdlabel -e ad10
# newfs /dev/ad10
# mount /dev/ad10a /mnt/temp
Une fois la partition créée et montée, il suffit de lancer Bonnie++ dans un dossier quelconque et d'analyser les résultats.
On constate que les performances sont inférieures aux attentes, indiquant potentiellement un mauvais alignement par rapport aux secteurs physiques.
Recherche du meilleur offset
Pour trouver l'alignement optimal, on recommence l'expérience précédente plusieurs fois en changeant l'offset. Il est également intéressant de faire un test d'écriture avec dd avant le test Bonnie, puis un test de lecture après pour comparer.
Pour réaliser ces mesures je me suis basé sur la configuration suivante :
- Disque WD15EARS (1.5To avec 64Mo de cache)
- Carte mère Intel DG965SS (ICH8)
- FreeBSD 8.0p2
- Bonnie++ v1.96 en procédant systématiquement à deux mesures
- Taille de bloc UFS = 4ko (newfs -b 4096 -f 512)
Le graphe suivant résume les résultats :
Le graphe montre clairement que l'alignement est assuré par défaut, contrairement à ce qu'on pouvait soupçonner. En effet, les meilleures vitesses en écriture sont obtenues avec un offset de 16 (défaut), puis avec un offset de 24, c'est-à-dire avec un offset supplémentaire de 4ko. Il est intéressant de noter que les performances en lecture séquentielle sont assez peu impactées par un mauvais alignement et on peut penser que c'est grâce au cache du disque qui contient forcément les secteurs lus récents, évitant ainsi une 2ième lecture.
Du coup, nous voilà pas spécialement plus avancés pour trouver l'origine des performances décevantes.
Une autre piste : la taille des blocs
Par défaut UFS utilise une taille de bloc de 16ko, ce qui semble en première approche convenable. Hélas ce n'est pas aussi simple : utiliser des blocs de 16ko implique une taille de fragments de 2ko parce qu'il est conseillé de préserver un rapport de 1/8. Selon le site de Sun, les fragments sont utilisés pour minimiser la fragmentation du système de fichiers en allouant des fragments de blocs plutôt que des blocs complets quand il n'en y a pas besoin.
Le problème est que ce disque WD ne sait pas écriture directement des blocs de 2ko, ayant lui-même des blocs de 4ko.
Pour étudier l'influence de la taille de bloc sur les performances, j'ai réalisé des benchmarks avec différentes tailles de blocs :
Il en ressort, sans surprise, qu'une taille de bloc de 32ko est bénéfique sur les performances, surtout que cela permettra au système de fichiers d'écrire systématiquement des blocs >= 4ko.
Conclusion
Contrairement à mes craintes initiales, l'alignement des secteurs est bien assuré si on opte pour un formatage natif. Par contre, il est intéressant d'augmenter la taille de blocs à 32ko en UFS parce que :
- Cela augmente les performances séquentielles
- Cela garantit une taille de fragment de 4ko
Historique
08/03/2010 - Version initiale
Posté le 03/03/10 à 18:58 - 0 Commentaires...

 ), il convient d'installer un logiciel
), il convient d'installer un logiciel